概述
Scrapy是一个基于Twisted异步网络库的爬虫框架,用Python编写,结构清晰,使用灵活。它的整体架构如下图所示,绿色箭头表示数据流向。
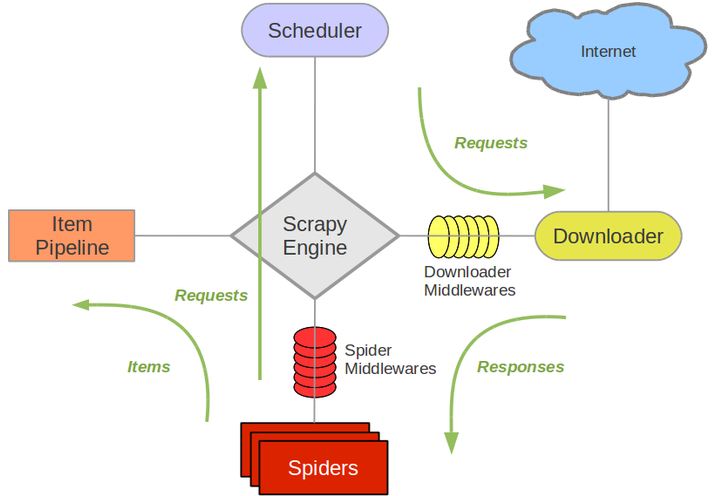
组件
Scrapy Engine
Scrapy引擎是用来控制整个系统的数据处理流程,并进行一些事件的触发。
Scheduler
调度器接受从Scrapy引擎的请求并将其入列,并在Scarpy引擎请求它们时,返回相应的请求。
Downloader
下载器负责抓取网页,并将相应的结果返回给Scrapy引擎和Spider
Spiders
Spider是用户自定义的爬虫类,用来解析响应并检索items添加额外的请求。每个Spider都能处理一个或者一组域名。
Item Pipeline
Pipeline主要负责处理Spider检索的items,典型的任务是清理、校验和持久化(如存储item至数据库)。
Downloader middlewares
Downloader middlewares(下载中间件)是位于Scrapy引擎和下载器之间的一个钩子,主要是处理Scrapy引擎与下载器之间的请求及响应,它提供了一种易于扩展Scrapy功能的机制。
Spider middlewares
Spider middlewares(Spider中间件)是介于Scrapy引擎和Spider之间的一个钩子,处理Spider的输入和输出,同样提供了一种易于扩展Scrapy功能的机制。
数据处理流程
- Scrapy引擎打开一个域名,并让Spider从
start_urls中的url请求数据 - 引擎将从Spider传过来的URLs传递给Scheduler
- 引擎向Scheduler请求下一条需要爬取的url
- Scheduler向引擎返回url,引擎将它们发送给Downloader(通过Downloader Middleware)
- 当下Downloader下载完网页后,生成响应并通过Downloader Middleware发送给引擎。
- 引擎接收从Downloader发送过来的响应,并发送给Spider处理(通过Spider Middleware)
- Spider处理响应,将爬取到的item和新的请求发送给引擎
- 引擎将Spider返回的item发送到Item Pipeline,将Spider返回的请求发送到Scheduler
- 重复第二步,直到Scheduler没有新的请求可用,然后引擎断开与域之间的联系
参考资料
http://doc.scrapy.org/en/0.18/topics/architecture.html