##mmseg4j分词 1 mmseg4j简介
mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法(http://technology.chtsai.org/mmseg/ )实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。
2 下载mmseg4j.jar
从mmseg4j项目下载mmseg4j-1.9.1.zip(当前最新版,支持solr4.3.1),解压,将dist目录下的mmseg4j-analysis/core/solr-1.9.1.jar拷贝至tomcat home/webapp/solr/WEB-INF/lib中
3 更新schema.xml
在solr.home目录/solr/collection1/conf目录下schema.xml文件中添加如下配置
<fieldType name="textComplex" class="solr.TextField" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"
mode="complex" dicPath="dic"/>
</analyzer>
</fieldType>
<fieldType name="textMaxWord" class="solr.TextField" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"
mode="max-word" dicPath="dic"/>
</analyzer>
</fieldType>
<fieldType name="textSimple" class="solr.TextField" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"
mode="simple" dicPath="n:/OpenSource/apache-solr-1.3.0/example/solr/my_dic"/>
</analyzer>
</fieldType>
4 测试
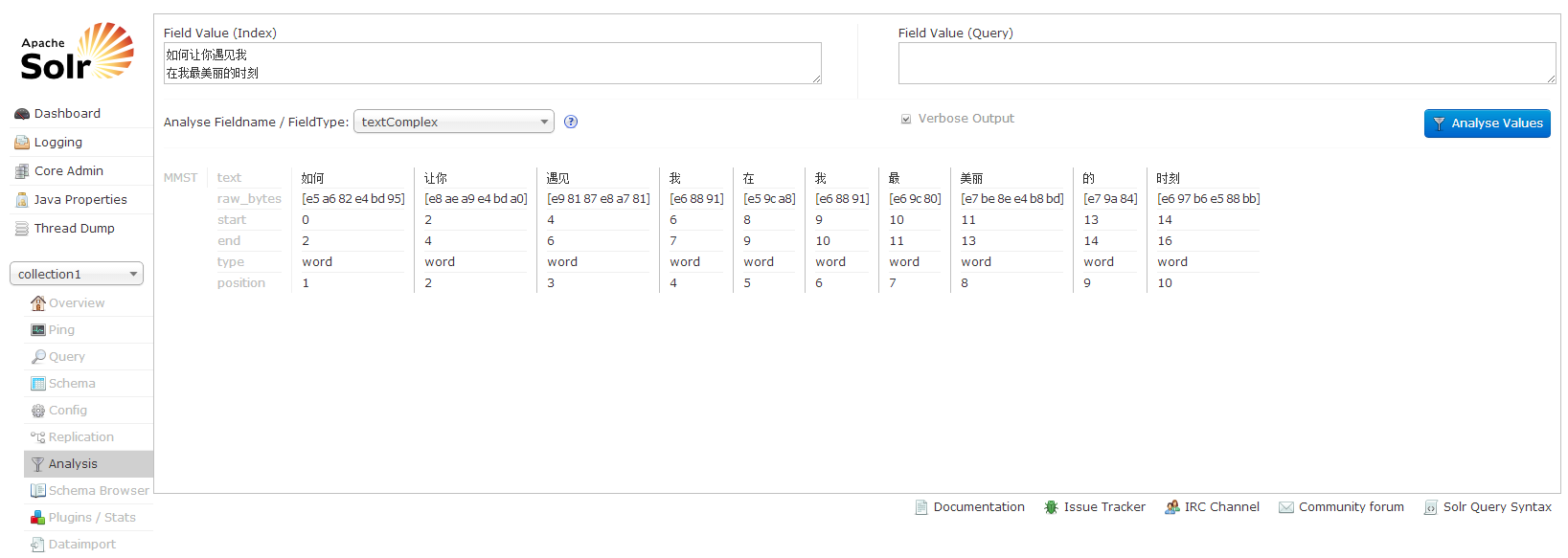
重启tomcat,访问Solr Analysis, http://localhost:8080/solr/#/collection1/analysis , 即在solr主界面下方,collection1->Anaylysis
在Field Value(Index)中输入 (如何让你遇见我 在我最美丽的时刻),FieldType选择(textComplex),结果如下